11.2.2.2.5 : Tableau, vecteur ou liste ?
Les tableaux, les std::vector et les std::list utilisent différemment l'espace mémoire (voir figure 32).
Les tableaux sont très indiqués pour stocker des données de types simples et vectorisables (float, int,~etc). Leur compréhension est intuitive car tous les éléments se traitent de la même façon. Le CPU et le compilateur sont bien plus efficaces pour traiter des tableaux à une seule dimension. Or, les analyses de physique utilisent des matrices et des tenseurs.
Si l'analyse a besoin d'une matrice $N\times M$ , il est préférable d'allouer un tableau de taille $N\times M$ et de le traiter comme une matrice. Ainsi, un élément à la i-ème ligne et à la j-ème colonne sera obtenu avec une adresse $i\times M + j$ si les données sont stockées en lignes (à la manière du C) ou $j\times N + i$ si les données sont stockées en colonnes (à la manière du Fortran).
Certaines propriétés, indispensables pour une vectorisation efficace (voir chapitre 11.3), peuvent également être ajoutées.
Il faut cependant être vigilant lorsque l'on utilise des tableaux en C ou en C++ afin d'éviter les fuites mémoire. Des outils comme Valgrind[60]Valgrind permettent de les détecter.
Les std::vector stockent des données quelconques sur une seule dimension. Les données stockées dans des std::vector en C++ 98 sont contiguës par bloc, les données des std::vector à partir de C++ 0 sont contiguës à la manière d'un tableau. Ils sont particulièrement efficaces lorsque de nouvelles données doivent être concaténées aux précédentes (une classe événement par exemple). Mais l'insertion de données au centre du tableau coûte bien plus cher que leur concaténation. Il est également difficile de les utiliser pour vectoriser des calculs (voir chapitre 11.3).
Les std::list offrent une très grande souplesse de manipulation de données au prix d'un surcoût important dans les tâches de recherche et de lecture. Elles sont efficaces pour de petits volumes de données (comme des configurations) mais leur performance se dégrade rapidement quand le volume de données augmente.
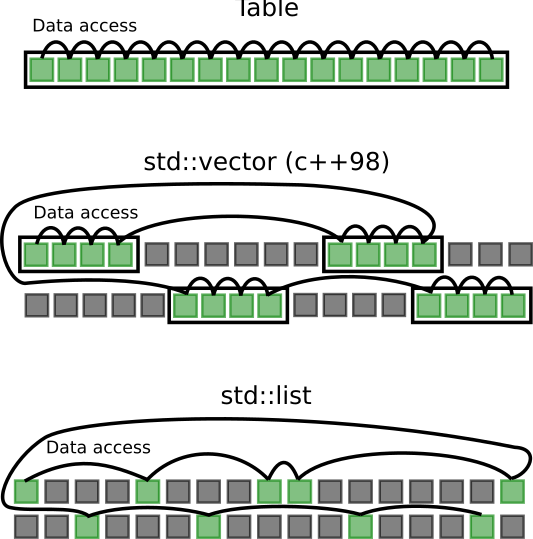
 Figure 32 : Différences de stockage entre les tables, les vectors (C++98) et les lists.
Figure 32 : Différences de stockage entre les tables, les vectors (C++98) et les lists.