5.2.4 : Caches CPU
Le mécanisme de cache a été introduit pour optimiser la vitesse de lecture des données de la RAM au CPU. Les caches sont classiquement au nombre de 4 (voir figure 8) :
- Le cache L1d de capacité $32\,$ kB : contient des données et est au plus près du CPU.
- Le cache L1i de capacité $32\,$ kB : pendant du cache L1d pour les instructions.
- Le cache L2 de capacité $256\,$ kB.
- Le cache L3 de capacité $8\,$ MB : le plus près de la RAM.
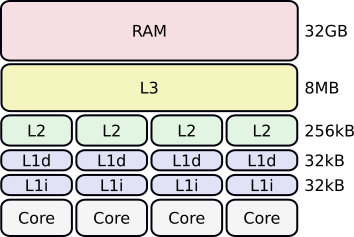
 Figure 8 : Caches dans un CPU.
Figure 8 : Caches dans un CPU.
Généralement les caches L1i, L1d et L2 sont dédiés par cœur tandis que le cache L3 est commun, au même titre que la RAM. Certain CPUs ont des caches L2 et L3 plus grands, respectivement de $1024\,$ kB et $16\,$ MB.
Le temps nécessaire pour accéder à une donnée est également différent. Typiquement, une donnée dans le cache L1d est lue en $1$ cycle noteUnité de temps de référence basée sur l'horloge des processeurs., dans le cache L2 en $6$ cycles, dans le cache L3 en $10$ cycles et dans la RAM en $25$ cycles ou plus.
Sans mécanisme de cache, un processeur ayant une fréquence d'horloge de $2\,$ GHz ne pourrait donc pas calculer à plus de $80\,$ MHz.
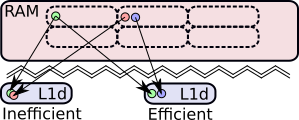
Figure 9 : Conflits d'accès au cache.
Selon le positionnement des données dans la RAM, des conflits peuvent apparaître (voir figure 9). En simplifiant, les adresses des données dans les caches seront obtenues par leurs adresses respectives dans la RAM modulo la taille du cache. Par conséquent, certaines données dont les adresses RAM sont différentes peuvent avoir des adresses identiques dans les caches.
Lorsque de tels conflits se produisent, la dernière donnée rapatriée chasse la donnée précédente. Or, si un calcul a besoin de ces deux données en même temps, le CPU devra chercher de nouveau la donnée perdue en RAM, ou dans un autre cache (L2 ou L3).
Ce phénomène est d'autant plus préoccupant que les constructeurs de CPUs ont ajouté un mécanisme dit de coloration de cache pour améliorer la vitesse de lecture de ces derniers. Mais il peut engendrer des conflits supplémentaires, car les caches sont découpés en $N$ couleurs afin d'accéder plus rapidement aux données qu'ils contiennent.
Par conséquent, les analyses ne doivent pas utiliser trop de tableaux dans le même calcul (idéalement moins que de couleurs de cache) et doivent utiliser une politique de pagination adéquate pour éviter ces problèmes qui dégradent fortement les performances de calculs.
Les OS ont différentes manières d'allouer de la mémoire aux applications et il peut arriver que certains fournissent des blocs de mémoire systématiquement alignés en RAM. Cela détériorera les performances d'un programme qui utilise de nombreux tableaux en même temps. Certains outils ont été développés pour atténuer ce problème en réimplémentant un allocateur [154]Introducing Kernel-level Page Reuse for High Performance Computing, 2013, Valat, S\'ebastien and P\'erache, Marc and Jalby, William.
Il n'existe pas à proprement parler de programmes capables de mesurer précisément l'utilisation du cache ou la localité des données.
Mais des outils comme perf [59]Perf ou Valgrind [60]Valgrind permettent d'évaluer le nombre de défauts de cache (cache-miss), et ainsi de mettre en évidence une mauvaise organisation des données. Certains programmes permettent aussi de visualiser les accès aux données dans la RAM, mais l'utilisateur doit alors déterminer lui-même quels emplacements mémoire correspondent à quelles données.
Mais des outils comme perf [59]Perf ou Valgrind [60]Valgrind permettent d'évaluer le nombre de défauts de cache (cache-miss), et ainsi de mettre en évidence une mauvaise organisation des données. Certains programmes permettent aussi de visualiser les accès aux données dans la RAM, mais l'utilisateur doit alors déterminer lui-même quels emplacements mémoire correspondent à quelles données.